This project showcases my expertise in web scraping, data processing, and workflow automation. The objective was to collect IT job offers from Pracuj.pl, extract detailed information, and store the data in a structured format for analysis. The process involved scraping job URLs, gathering detailed job offer data, and handling rate-limiting challenges effectively. Below, I detail the key sections of the project.
1. Project Overview
The main goal of the project was to automate the process of gathering and analyzing IT job offer data. Key steps included:
- Scraping job listing URLs from multiple pages.
- Extracting detailed information such as job titles, employer names, locations, requirements, and publication dates.
- Storing the data in a structured format (CSV) for further analysis.
- Implementing error-handling mechanisms and managing rate limits to ensure the scraper’s robustness and scalability.
Tech Stack: Python, SQL, DAX, Google Cloud (Google BigQuery)
Visualization Stack: Power BI
Web Scraping
- Script to Extract Job Offers URLs
- Script to Extract Website Data
Data Processing
- Main Script Integration
- Data Cleaning and Transformation
Data Storage
- Configuration Management
- Google BigQuery Integration
- Data Insertion and Updation
Data Analysis
- SQL Queries for Data Preparation
- Data Validation Queries
- Data Aggregation and Filtering
- Unpivot Views
- Power BI Integration
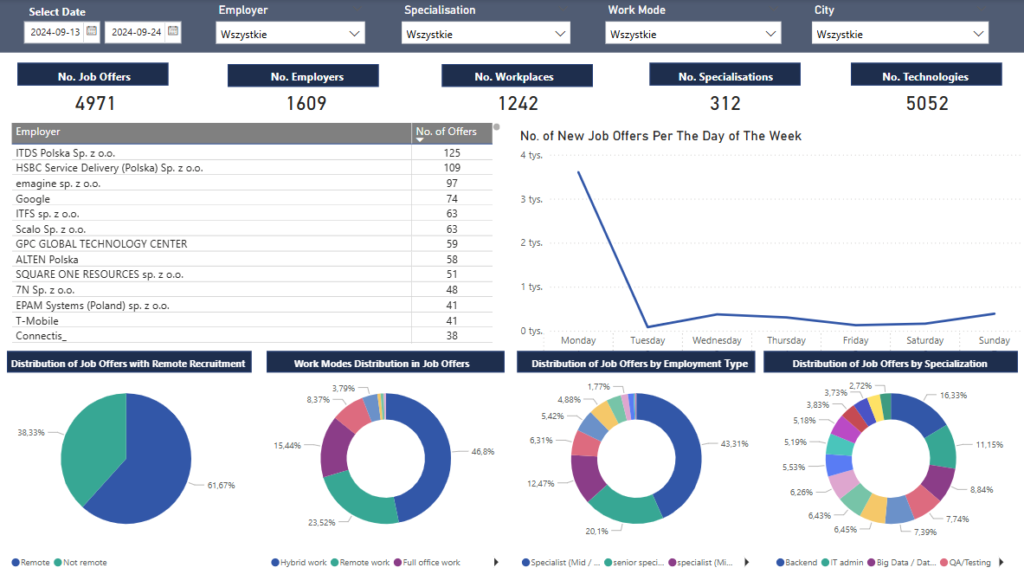
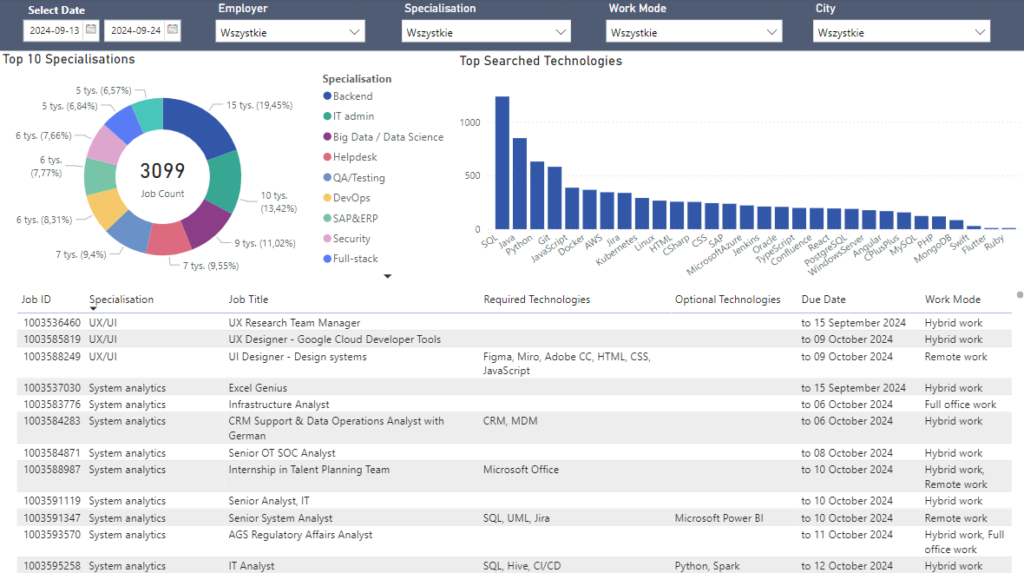
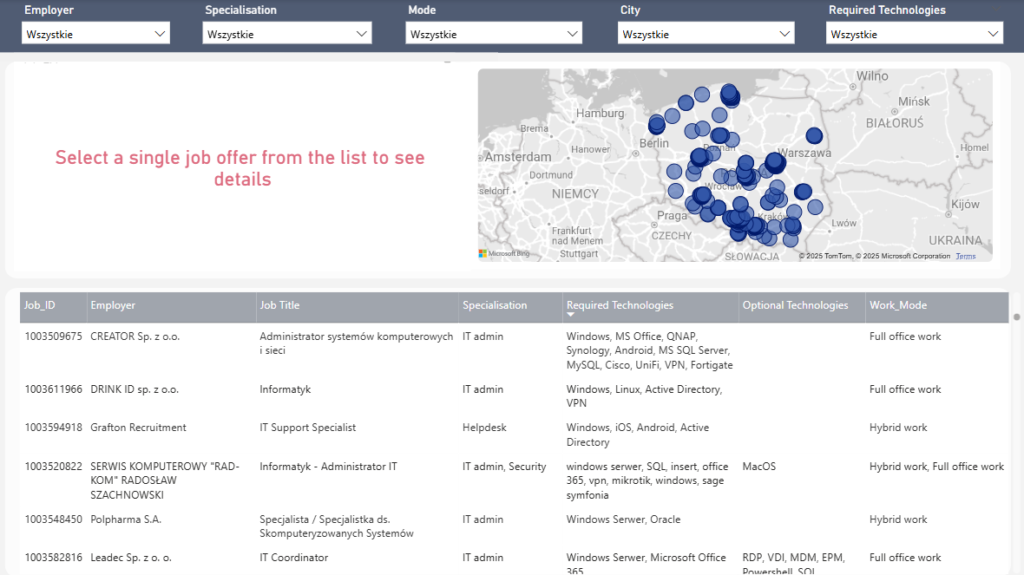
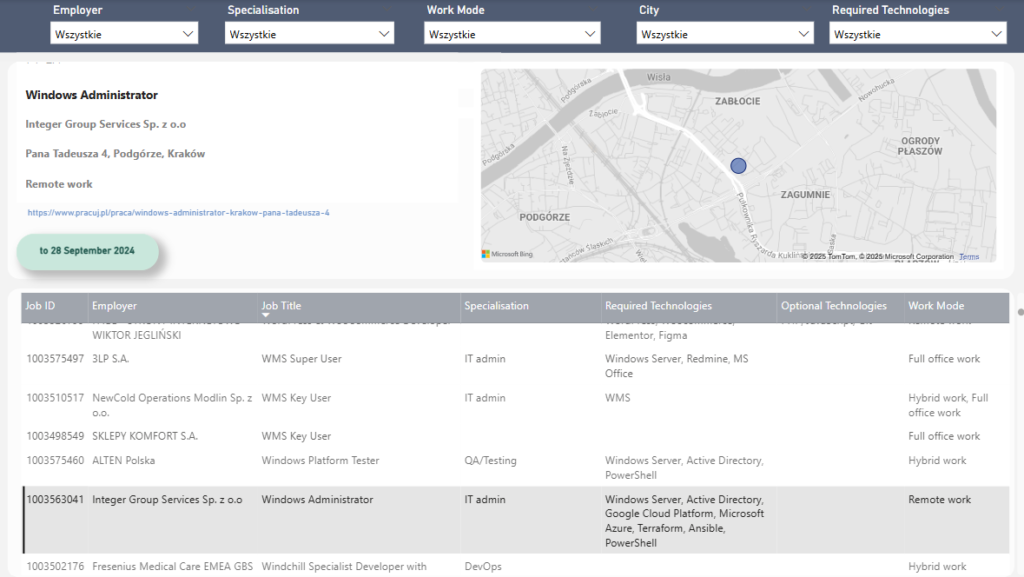
Dashboards Snippet:
1. Overview
2.Tech Career Explorer
3.Job Details
Web Scraping
1. Script to Extract Job URLs
import requests from bs4 import BeautifulSoup base_url = "https://it.pracuj.pl/praca?pn=" job_urls = [] for page_number in range(1, 70): url = base_url + str(page_number) response = requests.get(url) if response.status_code == 200: soup = BeautifulSoup(response.text, 'html.parser') for a_tag in soup.find_all('a', class_='tiles_c8yvgfl core_n194fgoq'): job_url = a_tag.get('href') if job_url and job_url.startswith("https://www.pracuj.pl/praca/"): job_urls.append(job_url) else: print(f"Failed to retrieve page {page_number}") for job_url in job_urls: print(job_url) with open("job_urls.txt", "w") as f: for job_url in job_urls: f.write(job_url + "\n")
The script loops through all pages of job listings, collecting individual job offer URLs. It ensures that only unique URLs are stored and handles failed page requests gracefully.
2. Script to Extract Website Data
For each job URL, detailed information is extracted, such as job title, employer name, location, technologies, and publication date. The data is structured into a dictionary and saved to a CSV file for analysis.
import requests from bs4 import BeautifulSoup import csv import time import random from datetime import datetime def scrape_job_details(job_url, retries=3): for attempt in range(retries): try: response = requests.get(job_url) if response.status_code == 429: sleep_time = 2 ** attempt + random.uniform(0, 1) + 10 time.sleep(sleep_time) continue response.raise_for_status() soup = BeautifulSoup(response.text, 'html.parser') job_title = soup.find('h1', {'data-test': 'text-positionName'}) job_title = job_title.text.strip() if job_title else 'N/A' employer_name = soup.find('h2', {'data-test': 'text-employerName'}) employer_name = employer_name.text.strip() if employer_name else 'N/A' workplace = soup.find('li', {'data-test': 'sections-benefit-workplaces'}) workplace = workplace.find('div', {'data-test': 'offer-badge-title'}).text.strip() if workplace else 'N/A' publication_date_section = soup.find('li', {'data-test': 'sections-benefit-expiration'}) publication_date = 'N/A' if publication_date_section: publication_date_div = publication_date_section.find('div', {'data-test': 'offer-badge-description'}) publication_date = publication_date_div.text.strip() if publication_date_div else 'N/A' agreement_type = soup.find('li', {'data-test': 'sections-benefit-contracts'}) agreement_type = agreement_type.find('div', {'data-test': 'offer-badge-title'}).text.strip() if agreement_type else 'N/A' employment_type_name = soup.find('li', {'data-test': 'sections-benefit-employment-type-name'}) employment_type_name = employment_type_name.find('div', {'data-test': 'offer-badge-title'}).text.strip() if employment_type_name else 'N/A' work_mode = soup.find('li', {'data-scroll-id': 'work-modes'}) work_mode = work_mode.find('div', {'data-test': 'offer-badge-title'}).text.strip() if work_mode else 'N/A' remote_recruitment = soup.find('li', {'data-scroll-id': 'remote-recruitment'}) remote_recruitment_status = 'Yes' if remote_recruitment else 'N/A' required_technologies_section = soup.find('div', {'data-test': 'section-technologies-expected'}) required_technologies = 'N/A' if required_technologies_section: required_technologies = ', '.join( li.text.strip() for li in required_technologies_section.find_all('li', {'data-test': 'item-technologies-expected'}) ) optional_technologies_section = soup.find('div', {'data-test': 'section-technologies-optional'}) optional_technologies = 'N/A' if optional_technologies_section: optional_technologies = ', '.join( li.text.strip() for li in optional_technologies_section.find_all('li', {'data-test': 'item-technologies-optional'}) ) specialisation_section = soup.find('li', {'data-test': 'it-specializations'}) specialisation = specialisation_section.find('div', class_='v1xz4nnx').text.strip() if specialisation_section else 'N/A' return { 'Job Title': job_title, 'Employer Name': employer_name, 'Workplace': workplace, 'Publication Date': publication_date, 'Agreement Type': agreement_type, 'Employment Type': employment_type_name, 'Work Mode': work_mode, 'Remote Recruitment': remote_recruitment_status, 'Required Technologies': required_technologies, 'Optional Technologies': optional_technologies, 'Specialisation': specialisation } except requests.RequestException: if attempt < retries - 1: sleep_time = 2 ** attempt + random.uniform(0, 1) + 10 time.sleep(sleep_time) else: return None def read_existing_jobs(filename): existing_jobs = {} try: with open(filename, 'r', newline='', encoding='utf-8') as csvfile: reader = csv.DictReader(csvfile) for row in reader: url = row.get('Job URL') if url: existing_jobs[url] = row except FileNotFoundError: pass return existing_jobs def write_jobs_to_csv(filename, jobs): with open(filename, 'w', newline='', encoding='utf-8') as csvfile: fieldnames = ['Job URL', 'Job Title', 'Employer Name', 'Workplace', 'Publication Date', 'Agreement Type', 'Employment Type', 'Work Mode', 'Remote Recruitment', 'Required Technologies', 'Optional Technologies', 'Specialisation', 'Status', 'Last Extraction Date'] writer = csv.DictWriter(csvfile, fieldnames=fieldnames) writer.writeheader() for job_url, job_data in jobs.items(): writer.writerow(job_data) def main(): base_url = "https://it.pracuj.pl/praca?pn=" job_urls = [] for page_number in range(1, 84): url = base_url + str(page_number) response = requests.get(url) if response.status_code == 200: soup = BeautifulSoup(response.text, 'html.parser') for a_tag in soup.find_all('a', class_='tiles_c8yvgfl core_n194fgoq'): job_url = a_tag.get('href') if job_url and job_url.startswith("https://www.pracuj.pl/praca/") and job_url not in job_urls: job_urls.append(job_url) existing_jobs = read_existing_jobs('job_details_23.09.2024.csv') new_jobs = {} for index, url in enumerate(job_urls, start=1): job_details = scrape_job_details(url) if job_details: job_details['Job URL'] = url job_details['Status'] = 'Updated' if url in existing_jobs else 'New' job_details['Last Extraction Date'] = datetime.now().strftime('%Y-%m-%d %H:%M:%S') new_jobs[url] = job_details if index % 10 == 0: time.sleep(5) write_jobs_to_csv('job_details_24.09.2024.csv', {**existing_jobs, **new_jobs}) if __name__ == "__main__": main()
3. Combining Data Stage
In this stage, I merged multiple CSV files into a single dataset to centralize all scraped job details for analysis. The script dynamically identified files in the target folder, loaded them into temporary DataFrames, and combined them using pandas.concat() while maintaining data integrity. The consolidated data was saved as a new CSV file, ready for further processing in Google BigQuery.
import pandas as pd import os directory = r"C:\Users\cem\Desktop\scraping pracuj.pl\job_details" csv_files = [os.path.join(directory, f) for f in os.listdir(directory) if f.endswith('.csv')] combined_df = pd.DataFrame() for file in csv_files: temp_df = pd.read_csv(file) combined_df = pd.concat([combined_df, temp_df], ignore_index=True) combined_df.to_csv(os.path.join(directory, "combined_job_details.csv"), index=False) print("Wszystkie pliki połączone do 'combined_job_details.csv'")
SQL:Data Cleaning and Transformation
To ensure consistency and accuracy, key data fields such as employment_type, agreement_type, and work_mode were cleaned and standardized. Utility functions were used to remove unwanted characters, convert data types, and handle missing values, resulting in a structured and reliable dataset.
Handling Missing Geo Data
This query defines two Common Table Expressions (CTEs). The first one, LocationData, filters rows from the job_details table to include only those with all required geographical fields present (Street, District, City, Latitude, and Longitude). The second CTE, RankedData, merges each row in job_details (including those missing geo information) with any matching record in LocationData by performing a LEFT JOIN on Job_ID.
In the final step, the query returns only those rows where row_num = 1, ensuring the result set contains the most complete and accurate geographical information for each Job_ID.
WITH LocationData AS ( SELECT Job_ID, Street, District, City, Latitude, Longitude FROM `joboffers-434919.job_offers.job_details` WHERE `Last Extraction Date` = '2024-09-24' AND Street IS NOT NULL AND District IS NOT NULL AND City IS NOT NULL AND Latitude IS NOT NULL AND Longitude IS NOT NULL ), RankedData AS ( SELECT DISTINCT j.Job_ID, COALESCE(j.Street, ld.Street, TRIM(REGEXP_EXTRACT(j.Workplace, r'^[^,]+'))) AS Street, COALESCE(j.District, ld.District, TRIM(REGEXP_EXTRACT(j.Workplace, r',\s*([^,]+),'))) AS District, COALESCE( j.City, ld.City, CASE WHEN NOT REGEXP_CONTAINS(j.Workplace, r',') THEN j.Workplace WHEN REGEXP_CONTAINS(j.Workplace, r'^[A-Za-z\s]+#39;
) THEN j.Workplace
ELSE TRIM(REGEXP_EXTRACT(j.Workplace, r',\s*([^,]+)#39;
))
END
) AS City,
COALESCE(j.Latitude, ld.Latitude) AS Latitude,
COALESCE(j.Longitude, ld.Longitude) AS Longitude,
ROW_NUMBER() OVER (
PARTITION BY j.Job_ID
ORDER BY
CASE WHEN COALESCE(j.Street, ld.Street) IS NOT NULL THEN 1 ELSE 2 END,
CASE WHEN COALESCE(j.District, ld.District) IS NOT NULL THEN 1 ELSE 2 END,
CASE WHEN COALESCE(j.City, ld.City) IS NOT NULL THEN 1 ELSE 2 END,
CASE WHEN COALESCE(j.Latitude, ld.Latitude) IS NOT NULL THEN 1 ELSE 2 END,
CASE WHEN COALESCE(j.Longitude, ld.Longitude) IS NOT NULL THEN 1 ELSE 2 END
) AS row_num
FROM `joboffers-434919.job_offers.job_details` j
LEFT JOIN LocationData ld ON j.Job_ID = ld.Job_ID
)SELECT Job_ID, Street, District, City, Latitude, Longitude
FROM RankedData
WHERE row_num = 1;
Cleaning Agreement Type Data
This query categorizes agreement types into standardized labels by matching specific text patterns via a CASE statement. It checks whether multiple types appear (e.g., if there are multiple commas or certain keyword combinations), then assigns an aggregated label such as “Any form of employment” or a more specific type.
SELECT DISTINCT Agreement_Type, CASE -- If there are more than 2 commas, categorize as 'Any form of employment' WHEN LENGTH(Agreement_Type) - LENGTH(REPLACE(Agreement_Type, ',', '')) > 2 THEN 'Any form of employment' -- Specific combinations added by the user (explicit 'Any form of employment' cases) WHEN Agreement_Type LIKE '%umowa zlecenie%' AND Agreement_Type LIKE '%umowa o pracê tymczasow¹%' AND Agreement_Type LIKE '%umowa o pracê%' AND Agreement_Type LIKE '%umowa o pracê tymczasow¹%' AND Agreement_Type LIKE '%umowa o dzie³o%' AND Agreement_Type LIKE '%kontrakt B2B%' THEN 'Any form of employment' WHEN Agreement_Type LIKE '%kontrakt B2B%' AND Agreement_Type LIKE '%umowa o pracê tymczasow¹%' AND Agreement_Type LIKE '%umowa zlecenie%' AND Agreement_Type LIKE '%umowa o sta¿ / praktyki%' AND Agreement_Type LIKE '%umowa o pracê%' AND Agreement_Type LIKE '%umowa na zastêpstwo%' THEN 'Any form of employment' WHEN Agreement_Type LIKE '%umowa o dzie³o%' AND Agreement_Type LIKE '%umowa zlecenie%' THEN 'Any form of employment' WHEN Agreement_Type LIKE '%contract for specific work%' AND Agreement_Type LIKE '%contract of mandate%' AND Agreement_Type LIKE '%B2B contract%' THEN 'Any form of employment' WHEN Agreement_Type LIKE '%contract of employment%' AND Agreement_Type LIKE '%substitution agreement%' THEN 'Any form of employment' WHEN Agreement_Type LIKE '%umowa o pracê%' AND Agreement_Type LIKE '%umowa o sta¿ / praktyki%' THEN 'Any form of employment' WHEN Agreement_Type LIKE '%B2B contract%' AND Agreement_Type LIKE '%temporary staffing agreement%' THEN 'Any form of employment' WHEN Agreement_Type LIKE '%contract of employment%' AND Agreement_Type LIKE '%agency agreement%' AND Agreement_Type LIKE '%umowa o pracê%' AND Agreement_Type LIKE '%umowa zlecenie%' THEN 'Any form of employment' WHEN Agreement_Type LIKE '%umowa o pracê%' AND Agreement_Type LIKE '%umowa zlecenie%' AND Agreement_Type LIKE '%kontrakt B2B%' THEN 'Any form of employment' WHEN Agreement_Type LIKE '%contract for specific work%' AND Agreement_Type LIKE '%B2B contract%' THEN 'Any form of employment' WHEN Agreement_Type LIKE '%B2B contract%' AND Agreement_Type LIKE '%agency agreement%' THEN 'Any form of employment' WHEN Agreement_Type LIKE '%umowa o sta¿ / praktyki%' THEN 'Any form of employment' WHEN Agreement_Type LIKE '%umowa na zastêpstwo%' THEN 'Any form of employment' WHEN Agreement_Type LIKE '%umowa o dzie³o%' AND Agreement_Type LIKE '%umowa agencyjna%' AND Agreement_Type LIKE '%umowa o pracê%' AND Agreement_Type LIKE '%kontrakt B2B%' AND Agreement_Type LIKE '%contract of mandate%' AND Agreement_Type LIKE '%B2B contract%' THEN 'Any form of employment' WHEN Agreement_Type LIKE '%B2B contract%' AND Agreement_Type LIKE '%substitution agreement%' THEN 'Any form of employment' -- Specific combinations as previously defined WHEN Agreement_Type LIKE '%umowa o pracę%' AND Agreement_Type LIKE '%umowa o dzieło%' AND Agreement_Type LIKE '%umowa zlecenie%' AND Agreement_Type LIKE '%kontrakt B2B%' AND Agreement_Type LIKE '%umowa o staż / praktyki%' THEN 'Employment contract, Contract for specific work, Contract of mandate, B2B contract, Internship / apprenticeship contract' WHEN Agreement_Type LIKE '%umowa o dzieło%' AND Agreement_Type LIKE '%umowa zlecenie%' AND Agreement_Type LIKE '%kontrakt B2B%' AND Agreement_Type LIKE '%umowa agencyjna%' AND Agreement_Type LIKE '%umowa o staż / praktyki%' THEN 'Contract for specific work, Contract of mandate, B2B contract, Agency agreement, Internship / apprenticeship contract' WHEN Agreement_Type LIKE '%umowa zlecenie%' AND Agreement_Type LIKE '%umowa o staż / praktyki%' THEN 'Contract of mandate, Internship / apprenticeship contract' WHEN Agreement_Type LIKE '%umowa o pracę%' AND Agreement_Type LIKE '%umowa zlecenie%' AND Agreement_Type LIKE '%umowa o staż / praktyki%' THEN 'Employment contract, Contract of mandate, Internship / apprenticeship contract' WHEN Agreement_Type LIKE '%umowa o pracę%' AND Agreement_Type LIKE '%umowa zlecenie%' AND Agreement_Type LIKE '%kontrakt B2B%' AND Agreement_Type LIKE '%umowa o staż / praktyki%' THEN 'Employment contract, Contract of mandate, B2B contract, Internship / apprenticeship contract' WHEN Agreement_Type LIKE '%umowa o dzieło%' AND Agreement_Type LIKE '%umowa zlecenie%' AND Agreement_Type LIKE '%kontrakt B2B%' AND Agreement_Type LIKE '%umowa o staż / praktyki%' THEN 'Contract for specific work, Contract of mandate, B2B contract, Internship / apprenticeship contract' WHEN Agreement_Type LIKE '%umowa zlecenie%' AND Agreement_Type LIKE '%umowa o pracę tymczasową%' THEN 'Contract of mandate, Temporary employment contract' WHEN Agreement_Type LIKE '%umowa zlecenie%' AND Agreement_Type LIKE '%kontrakt B2B%' AND Agreement_Type LIKE '%umowa o staż / praktyki%' THEN 'Contract of mandate, B2B contract, Internship / apprenticeship contract' WHEN Agreement_Type LIKE '%contract of employment%' AND Agreement_Type LIKE '%contract for specific work%' THEN 'Employment contract' WHEN Agreement_Type LIKE '%umowa o pracê, umowa o dzie³o%' THEN 'Employment contract' WHEN Agreement_Type LIKE '%contract of employment%' AND Agreement_Type LIKE '%B2B contract%' THEN 'Contract of mandate, B2B contract' WHEN Agreement_Type LIKE '%contract of mandate%' AND Agreement_Type LIKE '%internship / apprenticeship contract%' THEN 'Contract of mandate, Internship / apprenticeship contract' -- Single types (Polish) WHEN Agreement_Type LIKE '%umowa o pracê%' AND Agreement_Type NOT LIKE '%,%' THEN 'Employment contract' WHEN Agreement_Type LIKE '%umowa o pracę%' AND Agreement_Type NOT LIKE '%,%' THEN 'Employment contract' WHEN Agreement_Type LIKE '%umowa o dzieło%' AND Agreement_Type NOT LIKE '%,%' THEN 'Contract for specific work' WHEN Agreement_Type LIKE '%umowa o dzie³o%' AND Agreement_Type NOT LIKE '%,%' THEN 'Contract for specific work' WHEN Agreement_Type LIKE '%umowa zlecenie%' AND Agreement_Type NOT LIKE '%,%' THEN 'Contract of mandate' WHEN Agreement_Type LIKE '%umowa o staż / praktyki%' AND Agreement_Type NOT LIKE '%,%' THEN 'Internship / apprenticeship contract' WHEN Agreement_Type LIKE '%kontrakt B2B%' AND Agreement_Type NOT LIKE '%,%' THEN 'B2B contract' WHEN Agreement_Type LIKE '%umowa agencyjna%' AND Agreement_Type NOT LIKE '%,%' THEN 'Agency agreement' WHEN Agreement_Type LIKE '%umowa o pracę tymczasową%' AND Agreement_Type NOT LIKE '%,%' THEN 'Temporary employment contract' WHEN Agreement_Type LIKE '%umowa o pracê tymczasow¹%' AND Agreement_Type NOT LIKE '%,%' THEN 'Temporary employment contract' WHEN Agreement_Type LIKE '%umowa na zastępstwo%' AND Agreement_Type NOT LIKE '%,%' THEN 'Substitution agreement' -- Single types (English) WHEN Agreement_Type LIKE '%contract of employment%' AND Agreement_Type NOT LIKE '%,%' THEN 'Employment contract' WHEN Agreement_Type LIKE '%contract for specific work%' AND Agreement_Type NOT LIKE '%,%' THEN 'Contract for specific work' WHEN Agreement_Type LIKE '%contract of mandate%' AND Agreement_Type NOT LIKE '%,%' THEN 'Contract of mandate' WHEN Agreement_Type LIKE '%internship / apprenticeship contract%' AND Agreement_Type NOT LIKE '%,%' THEN 'Internship / apprenticeship contract' WHEN Agreement_Type LIKE '%B2B contract%' AND Agreement_Type NOT LIKE '%,%' THEN 'B2B contract' WHEN Agreement_Type LIKE '%agency agreement%' AND Agreement_Type NOT LIKE '%,%' THEN 'Agency agreement' WHEN Agreement_Type LIKE '%temporary staffing agreement%' AND Agreement_Type NOT LIKE '%,%' THEN 'Temporary employment contract' WHEN Agreement_Type LIKE '%substitution agreement%' AND Agreement_Type NOT LIKE '%,%' THEN 'Substitution agreement' -- English combinations WHEN Agreement_Type LIKE '%contract of employment%' AND Agreement_Type LIKE '%contract of mandate%' AND Agreement_Type LIKE '%B2B contract%' THEN 'Employment contract, Contract of mandate, B2B contract' WHEN Agreement_Type LIKE '%contract of employment%' AND Agreement_Type LIKE '%contract for specific work%' AND Agreement_Type LIKE '%B2B contract%' THEN 'Employment contract, Contract for specific work, B2B contract' -- for any other combinations ELSE 'Any form of employment' END AS Standardized_Agreement_Type FROM `joboffers-434919.job_offers.complete_job_details` ORDER BY Standardized_Agreement_Type;
Cleaning Work Mode Data
SELECT DISTINCT Work_Mode AS Work_Mode, CASE WHEN Work_Mode IS NULL THEN 'Not specified' -- Grouping combinations: -- Case where hybrid, full office, and home office work are combined WHEN Work_Mode LIKE '%hybrid work%' AND Work_Mode LIKE '%home office work%' AND Work_Mode LIKE '%full office work%' THEN 'Any type of work mode' -- Two types combinations WHEN Work_Mode LIKE '%home office work%' AND Work_Mode LIKE '%hybrid work%' THEN 'Hybrid work, Remote work' WHEN Work_Mode LIKE '%home office work%' AND Work_Mode LIKE '%full office work%' THEN 'Full office work, Remote work' WHEN Work_Mode LIKE '%hybrid work%' AND Work_Mode LIKE '%full office work%' THEN 'Hybrid work, Full office work' WHEN Work_Mode LIKE '%home office work%' AND Work_Mode LIKE '%praca hybrydowa%' THEN 'Hybrid work, Remote work' WHEN Work_Mode LIKE '%full office work%' AND Work_Mode LIKE '%praca zdalna%' THEN 'Full office work, Remote work' WHEN Work_Mode LIKE '%hybrid work%' AND Work_Mode LIKE '%praca stacjonarna%' THEN 'Hybrid work, Full office work' WHEN Work_Mode LIKE '%praca hybrydowa%' AND Work_Mode LIKE '%praca stacjonarna%' THEN 'Hybrid work, Full office work' WHEN Work_Mode LIKE '%praca zdalna%' AND Work_Mode LIKE '%praca stacjonarna%' THEN 'Full office work, Remote work' -- Single work modes: WHEN Work_Mode LIKE '%praca stacjonarna%' THEN 'Full office work' WHEN Work_Mode LIKE '%praca zdalna%' THEN 'Remote work' WHEN Work_Mode LIKE '%praca hybrydowa%' THEN 'Hybrid work' WHEN Work_Mode LIKE '%praca mobilna%' THEN 'Mobile work' -- Single English modes: WHEN Work_Mode LIKE '%home office work%' THEN 'Remote work' WHEN Work_Mode LIKE '%full office work%' THEN 'Full office work' WHEN Work_Mode LIKE '%hybrid work%' THEN 'Hybrid work' WHEN Work_Mode LIKE '%mobile work%' THEN 'Mobile work' ELSE 'Any type of work mode' -- fallback for any other cases END AS Translated_Work_Mode FROM `joboffers-434919.job_offers.complete_job_details` ORDER BY Work_Mode;
Creating final view
This query unifies job details from multiple tables by joining and standardizing fields such as Employment Type, Work Mode, and Agreement Type. It produces a consolidated dataset—intended as the final view for the Power BI dashboard—that includes consistent geolocation data, formatted dates, and standardized job attributes.
SELECT jd.`Job URL` AS Job_URL, CAST(jd.Job_id AS INT64) AS Job_ID, jd.`Job Title` AS Job_Title, jd.`Employer Name` AS Employer_Name, jd.Workplace, jd.`Publication Date` AS Publication_Date, COALESCE(et.Translated_Employment_Type, jd.`Employment Type`) AS Employment_Type, COALESCE(wm.Translated_Work_Mode, jd.`Work Mode`) AS Work_Mode, COALESCE(ag.Standardized_Agreement_Type, jd.`Agreement Type`) AS Agreement_Type, CASE WHEN jd.`Remote Recruitment` = TRUE THEN 'Yes' WHEN jd.`Remote Recruitment` IS NULL THEN 'No' ELSE 'No' END AS Remote_Recruitment, jd.`Required Technologies` AS Required_Technologies, jd.`Optional Technologies` AS Optional_Technologies, jd.Specialisation, jd.Status, PARSE_DATE('%d.%m.%Y', SUBSTR(jd.`Last Extraction Date`, 1, 10)) AS Last_Extraction_Date, FORMAT_DATE('%A', PARSE_DATE('%d.%m.%Y', SUBSTR(jd.`Last Extraction Date`, 1, 10))) AS Original_Day_of_Week, COALESCE(ld.City, c.FixedCityName) AS City, COALESCE(CAST(jd.Latitude AS FLOAT64), CAST(ld.Latitude AS FLOAT64)) AS Latitude, COALESCE(CAST(jd.Longitude AS FLOAT64), CAST(ld.Longitude AS FLOAT64)) AS Longitude FROM `joboffers-434919.job_offers.job_details` jd LEFT JOIN `joboffers-434919.job_offers.location_data` ld ON jd.Job_id = ld.Job_ID LEFT JOIN `joboffers-434919.job_offers.City` c ON jd.City = c.City LEFT JOIN `joboffers-434919.job_offers.Employment_type` et ON jd.`Employment Type` = et.Employment_Type LEFT JOIN `joboffers-434919.job_offers.Type_of_agreement` ag ON jd.`Agreement Type` = ag.Agreement_Type LEFT JOIN `joboffers-434919.job_offers.Work_mode` wm ON jd.`Work Mode` = wm.Work_Mode;
Dashboard Creation with DAX: Examples and Use Cases
-- Determines the background color based on whether a job is selected BackgroundColor = IF( ISFILTERED('stg_job_details_final'[Job_ID]), "#FFFFFF00", -- Transparent background "#FFFFFF" -- Visible background ) -- Counts the number of specializations that are not blank Specialisation_Count = COUNTX( FILTER( 'stg_job_details_final', NOT(ISBLANK('stg_job_details_final'[Specialisation])) ), 'stg_job_details_final'[Specialisation] ) -- Calculates the total number of job postings TotalJobs = COUNTROWS('stg_job_details_final') -- Counts the number of unique job locations UniqueLocations = DISTINCTCOUNT('stg_job_details_final'[City]) -- Determines the percentage of remote job offers RemoteJobsPercentage = DIVIDE( COUNTROWS(FILTER('stg_job_details_final', 'stg_job_details_final'[Work_Mode] = "Remote")), TotalJobs, 0 ) -- Computes the average salary based on available salary data AverageSalary = AVERAGEX( FILTER('stg_job_details_final', NOT(ISBLANK('stg_job_details_final'[Salary]))), 'stg_job_details_final'[Salary] ) -- Counts the number of jobs available for each agreement type AgreementTypeCount = SUMMARIZE( 'stg_job_details_final', 'stg_job_details_final'[Agreement_Type], "Job Count", COUNTROWS('stg_job_details_final') )